Un benchmark conçu pour éviter la contamination des modèles
Alors que les principaux benchmarks publics de codage commencent à saturer, les modèles les plus avancés se regroupant dans une bande de scores étroite où les intervalles de confiance se chevauchent souvent, un nouveau benchmark nommé DeepSWE a été présenté par la société Datacurve. Ce benchmark se veut un outil de mesure plus discriminant pour les agents de codage dits « frontière ».
DeepSWE repose sur quatre innovations principales. La première est l'absence totale de contamination : les tâches sont rédigées de toutes pièces, et non adaptées à partir de commits ou de demandes d'extension (« pull requests ») existants. Ainsi, aucun modèle n'a pu rencontrer la solution lors de son pré-entraînement. Les créateurs du benchmark précisent que certaines tâches sont motivées par des problèmes non résolus sur GitHub, mais que la correction elle-même est inédite. De plus, ces tâches ne sont jamais fusionnées dans les dépôts amont, ce qui empêche leur apparition dans les futurs corpus d'entraînement.
Une diversité et une complexité accrues
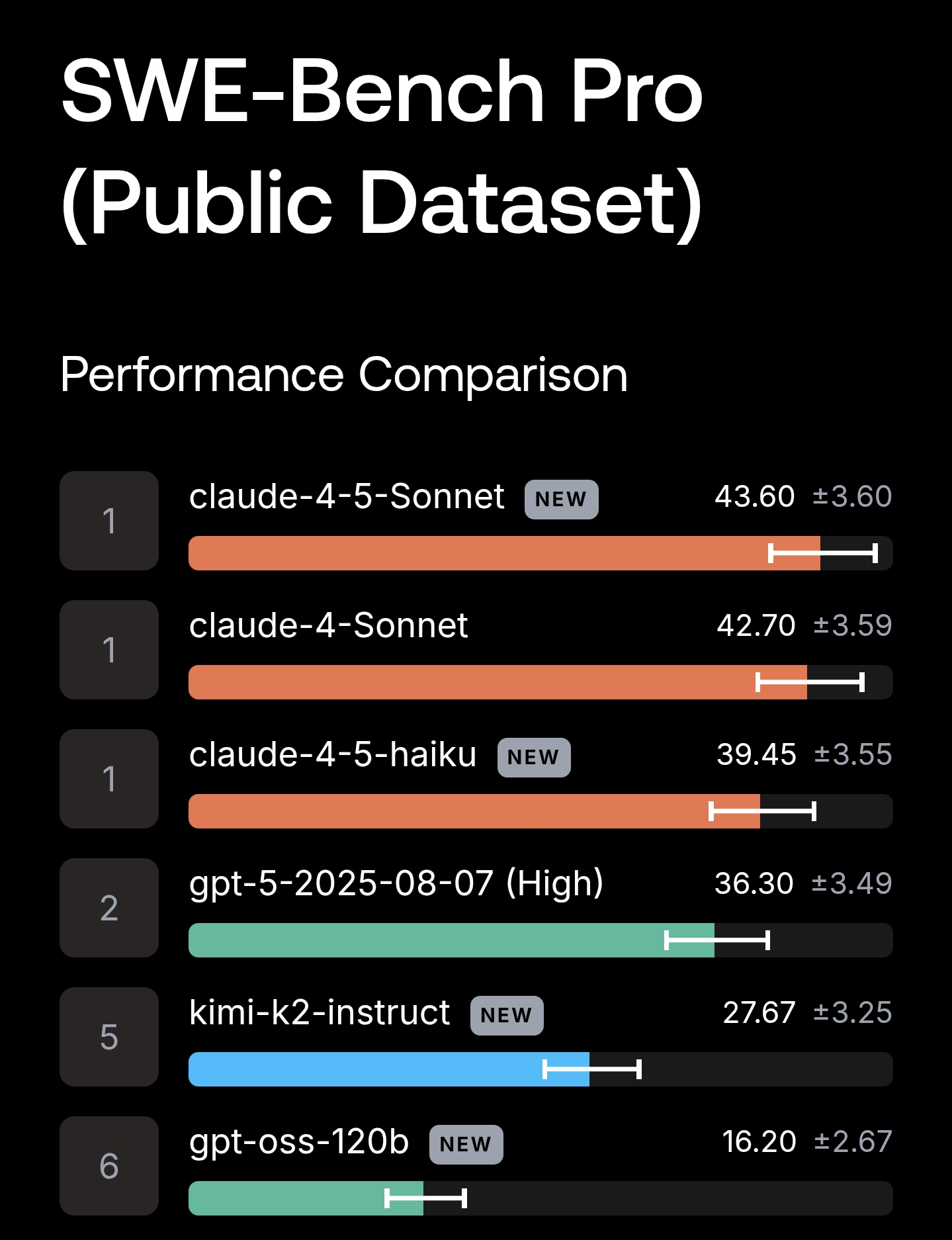
DeepSWE propose 113 tâches réparties sur 91 dépôts open source actifs, couvrant cinq langages de programmation : TypeScript (31 % des tâches), Go (30 %), Python (30 %), JavaScript (4 %) et Rust (4 %). Cette diversité contraste avec les benchmarks existants comme SWE-Bench Pro Public et SWE-Bench Verified, qui ne couvrent respectivement que 11 et 12 dépôts.
Les tâches de DeepSWE sont également plus complexes. Alors que les instructions (prompts) sont en moyenne plus courtes (2 158 caractères contre 4 614 pour SWE-Bench Pro), les solutions de référence ajoutent en moyenne 668 lignes de code, contre 120 pour SWE-Bench Pro et seulement 10 pour SWE-Bench Verified. Les agents doivent en moyenne modifier sept fichiers par tâche, contre cinq pour SWE-Bench Pro. Les créateurs soulignent que les instructions sont alignées sur la manière dont les développeurs parlent à leurs agents : centrées sur le comportement attendu, courtes et sans longs blocs de définition d'interface. Les agents doivent ainsi découvrir où et comment implémenter le changement, ce qui met l'accent sur l'exploration de bout en bout.
Des vérificateurs comportementaux pour plus de fiabilité
Un autre apport majeur de DeepSWE réside dans ses vérificateurs (verifiers). Ceux-ci sont rédigés à la main et testent le comportement du logiciel plutôt que les détails d'implémentation. Selon l'équipe de Datacurve, un audit du vérificateur de SWE-bench Pro a révélé des taux d'erreur de 8 % de faux positifs et 24 % de faux négatifs dans l'évaluation des sorties des agents. DeepSWE vise à fournir une mesure plus fiable.
Résultats : des écarts marqués entre les modèles
Le classement (leaderboard) publié par Datacurve, obtenu avec l'outil d'évaluation mini-swe-agent, montre des écarts significatifs entre les modèles. En tête, le modèle gpt-5.5 affiche un taux de réussite de 70 % (±4 %), suivi par gpt-5.4 (56 % ±5 %) et claude-opus-4.7 (54 % ±5 %). Plus loin, on trouve claude-sonnet-4.6 (32 % ±4 %), gemini-3.5-flash (28 % ±4 %), puis une série de modèles entre 24 % et 5 %, comme gpt-5.4-mini, kimi-k2.6, mimo-v2.5-pro, glm-5.1, gemini-3.1-pro, deepseek-v4-pro et gemini-3-flash. Les créateurs notent que les modèles qui semblent proches sur les benchmarks publics se séparent ici en écarts larges et ordonnés, correspondant mieux aux différences perçues par les développeurs dans l'utilisation quotidienne des agents.
Analyse qualitative des échecs
L'équipe de Datacurve a également mené une analyse qualitative des résultats. Selon leurs observations, le modèle Claude a tendance à ne pas respecter toutes les exigences, tandis que GPT suit mieux les instructions. Les modèles les plus performants font preuve d'une capacité d'auto-vérification (self-test) au cours de leurs sessions de codage. Les schémas d'échec sur le benchmark SWE-Bench Pro sont également reproduits dans DeepSWE.
Limites et perspectives
Les auteurs reconnaissent plusieurs limites à leur travail. La construction manuelle des tâches et des vérificateurs est coûteuse et limite la taille du benchmark. De plus, les instructions, bien que courtes, peuvent parfois être ambiguës. Les travaux futurs pourraient inclure l'élargissement du nombre de tâches et l'amélioration des vérificateurs. L'objectif affiché est de fournir une référence plus fiable pour la communauté de recherche en intelligence artificielle, alors que les préoccupations concernant la contamination des benchmarks se multiplient.