Les défis des pipelines d'IA en production
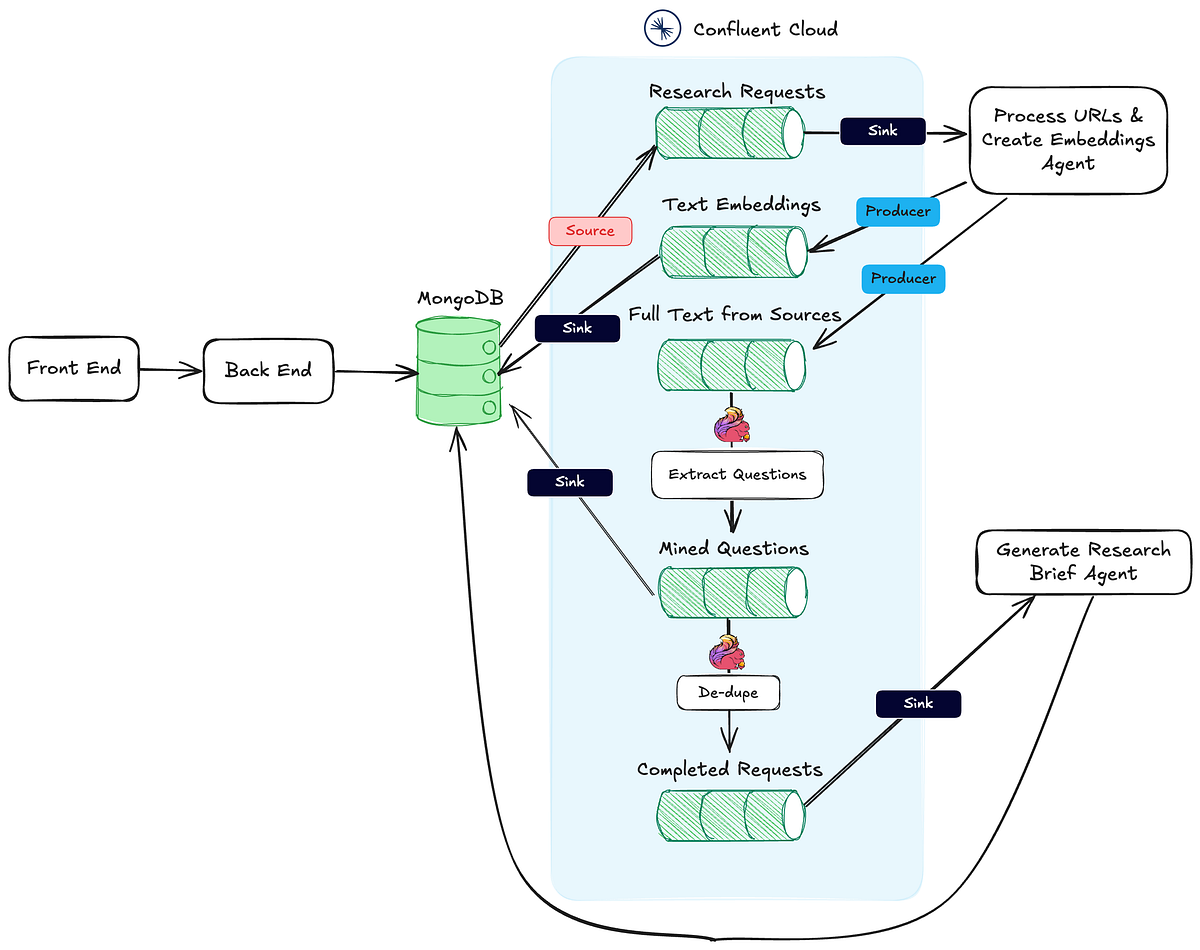
Les systèmes d’intelligence artificielle échouent rarement en production à cause du modèle lui-même. Plus souvent, ce sont les infrastructures sous-jacentes, conçues pour des charges de travail traditionnelles, qui posent problème. En production, les charges de travail IA introduisent une latence variable, des reprises, des pics de concurrence, une contre-pression et des problèmes de contrôle d’accès multi-locataires que les systèmes synchrones peinent à gérer. Le démonstrateur peut fonctionner avec des chaînes requête-réponse HTTP, mais la production est un tout autre environnement : des milliers d’utilisateurs soumettent des requêtes simultanément tandis qu’un LLM prend huit secondes pour répondre, un service d’embedding atteint des limites de débit alors que le trafic d’ingestion continue d’arriver, ou une requête relancée crée par inadvertance des embeddings en double dans la base vectorielle. Ces problèmes ne sont pas des problèmes de modèle, mais des problèmes d’infrastructure.
Le rôle de Kafka
Apache Kafka, la plateforme de streaming événementiel, répond à ces besoins grâce à son découplage asynchrone, sa capacité de relecture (replay) et sa gestion de la contre-pression (backpressure). Kafka permet de dissocier les producteurs de données des consommateurs, ce qui est crucial lorsque les temps de réponse des modèles d’IA sont imprévisibles. En outre, la persistance des messages dans Kafka autorise une relecture en cas d’échec, évitant ainsi les duplications d’embeddings. La contre-pression intégrée de Kafka empêche l’accumulation excessive de messages si un service en aval ralentit. Cependant, Kafka seul ne suffit pas pour un pipeline d’IA moderne : il lui manque une couche d’identité, de filtrage d’accès et de schémas adaptée aux usages multi-locataires.
Comment Zilla rend Kafka prêt pour l’IA
La société Aklivity a développé Zilla, un gateway multi-protocole natif du streaming, qui complète Kafka pour les pipelines d’IA. Zilla ajoute plusieurs fonctionnalités clés : l’authentification et l’autorisation via des jetons JWT, la validation des schémas, le filtrage d’accès granulaire, et la prise en charge du protocole SSE (Server-Sent Events) pour diffuser des données en temps réel aux applications d’IA. Grâce à Zilla, il devient possible d’appliquer des politiques de sécurité au niveau des champs de messages, de limiter l’accès à certaines parties des événements en fonction du rôle de l’utilisateur, et d’exposer des API de streaming standard aux applications clientes sans exposer directement les brokers Kafka. Zilla transforme ainsi Kafka en une plateforme de données prête pour l’IA, capable de gérer les identités, les schémas et les accès multi-locataires sans nécessiter de code personnalisé.
Implications pour les architectures d’IA
Cette approche permet aux équipes de déployer des pipelines RAG (Retrieval-Augmented Generation) plus robustes et sécurisés, où les accès aux données sont contrôlés finement et où les flux événementiels sont protégés contre les défaillances de latence et les surcharges. En combinant Kafka et Zilla, il devient possible de construire des systèmes d’IA qui restent fiables même sous forte charge, avec une séparation claire entre l’infrastructure de streaming et les applications d’IA. L’entreprise Aklivity illustre ainsi une tendance plus large : l’adaptation des infrastructures de données temps réel aux spécificités des workloads d’intelligence artificielle, afin d’éviter les échecs en production liés aux goulots d’étranglement et aux problèmes d’autorisation.



