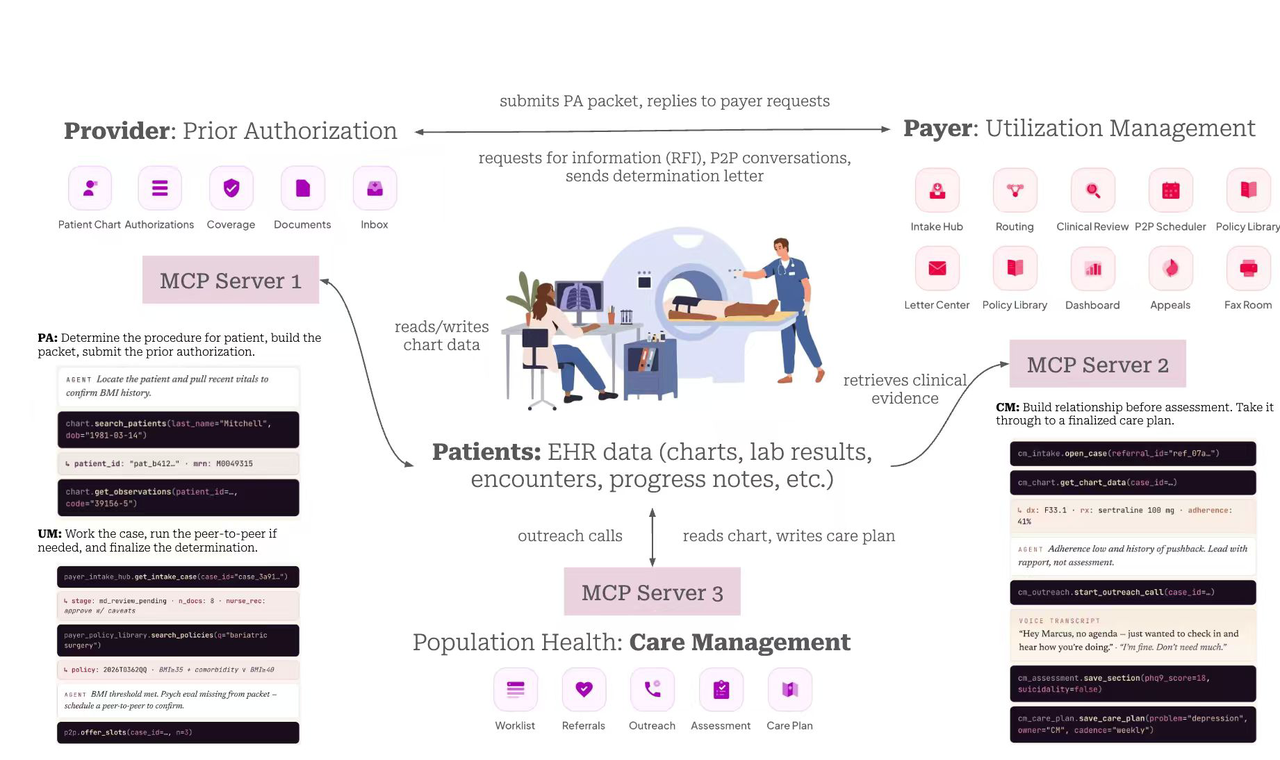
Les modèles d’intelligence artificielle les plus avancés, y compris Claude d’Anthropic, GPT d’OpenAI et Gemini de Google, échouent à 72 % des flux de travail typiques du système de santé américain, selon un nouveau benchmark publié récemment. L’étude, conçue pour évaluer la capacité des agents d’IA à gérer des tâches réelles et complexes, montre que les performances des systèmes sont loin des attentes nécessaires pour une adoption clinique fiable.
L’évaluation a porté sur un ensemble diversifié de tâches incluant la gestion des dossiers médicaux, la coordination des soins, le codage de facturation, la planification des rendez-vous et la vérification des autorisations préalables. Sur l’ensemble de ces workflows, les agents ont obtenu un taux de succès moyen de seulement 28 %, soit moins d’une tâche sur trois. Les résultats varient selon les modèles, mais aucun n’a dépassé le seuil des 35 % de réussite sur la totalité des épreuves.
Les chercheurs à l’origine du benchmark soulignent que ces résultats révèlent des lacunes fondamentales dans la compréhension contextuelle et la capacité à enchaîner des actions complexes propres aux environnements de soins. Les erreurs les plus fréquentes concernent des interprétations erronées de consignes médicales ambiguës, l’incapacité à respecter les contraintes réglementaires américaines (HIPAA, codage ICD-10, etc.) et des échecs dans la gestion des exceptions procédurales.
Des implications directes pour la sécurité des patients
Au-delà de la performance pure, l’étude insiste sur les risques potentiels en matière de sécurité des patients. Un agent qui échoue à planifier correctement un suivi ou à transmettre une information clé pourrait entraîner des retards de diagnostic ou des traitements inappropriés. Les auteurs appellent à une prudence accrue avant de déployer ces technologies dans des contextes où une erreur humaine est déjà délétère.
Les experts contactés par les rédacteurs de l’étude estiment que le principal obstacle réside dans la conception même des agents actuels : ils sont entraînés sur des corpus généraux et manquent de spécialisation dans le domaine médical. Les flux de travail en santé sont par nature interconnectés et soumis à des règles changeantes, ce que les modèles généralistes peinent à modéliser.
Un benchmark conçu pour pousser l’industrie à progresser
Ce nouveau benchmark a été spécifiquement construit pour être reproductible et transparent, afin que les développeurs d’IA puissent identifier les faiblesses de leurs systèmes. Les concepteurs espèrent que la publication de ces résultats encouragera les entreprises à investir dans l’affinage des modèles sur des données médicales réelles et à renforcer les mécanismes de contrôle et de correction d’erreurs.
Les résultats interviennent dans un contexte où de nombreux hôpitaux et assurances américains expérimentent déjà des agents conversationnels pour automatiser certaines tâches administratives. L’écart entre les promesses des fournisseurs d’IA et les performances mesurées sur le terrain soulève des inquiétudes quant à un déploiement prématuré.
Des perspectives nuancées
Si les chiffres sont préoccupants, les chercheurs notent que les modèles progressent rapidement et que des améliorations ciblées pourraient relever significativement leur taux de réussite. Des approches comme l’apprentissage par renforcement supervisé spécifique au domaine médical, l’intégration de bases de connaissances externes (ontologies médicales) et l’ajout de boucles de vérification humaine pourraient permettre d’atteindre des niveaux de fiabilité acceptables dans les prochaines années.
Cependant, la publication insiste sur le fait qu’à ce stade, aucun agent d’IA n’est apte à remplacer, même partiellement, un professionnel de santé dans la gestion autonome des workflows. La recommandation actuelle est de considérer ces outils comme des aides limitées, sous supervision humaine stricte.



