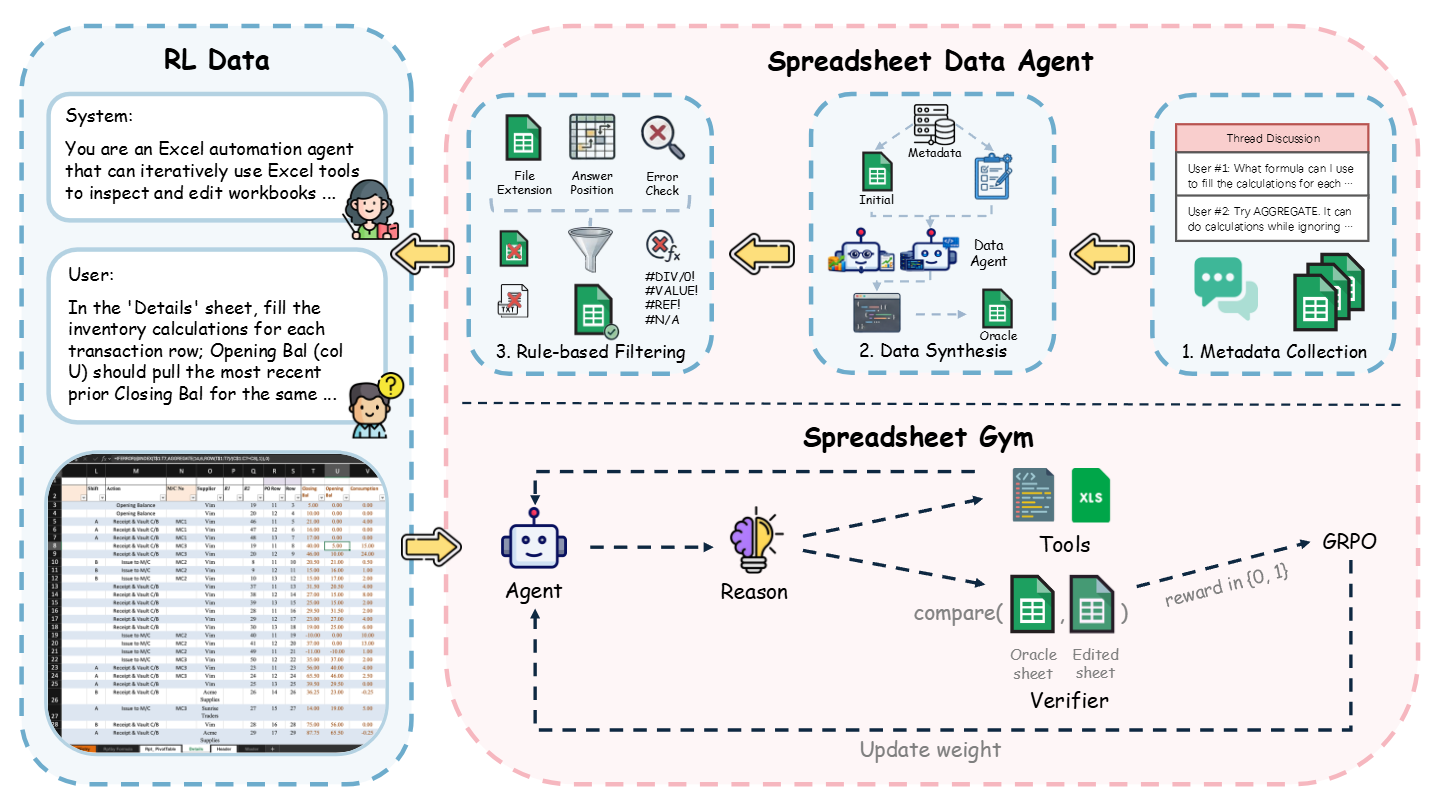
Un cadre d'apprentissage par renforcement pour les tableurs
Des chercheurs ont dévoilé Spreadsheet-RL, un nouveau cadre d'apprentissage par renforcement conçu pour former les agents basés sur de grands modèles de langage (LLM) à accomplir des tâches complexes et réalistes sur des tableurs. Cette approche vise à combler le fossé entre les capacités actuelles des LLM et les exigences pratiques de la manipulation de données dans des environnements de type tableur, où les actions sont séquentielles et dépendantes du contexte.
Principes et fonctionnement
Spreadsheet-RL s'appuie sur l'apprentissage par renforcement pour permettre à l'agent d'apprendre par l'essai et l'erreur. L'agent reçoit une récompense lorsqu'il effectue une action correcte (par exemple, appliquer une formule, copier une cellule) et une pénalité en cas d'erreur. Le système intègre également un mécanisme d'exploration qui encourage l'agent à essayer différentes stratégies pour résoudre un problème, plutôt que de se contenter de reproduire des solutions vues lors de l'entraînement.
Des tâches réalistes et variées
Le cadre a été testé sur un ensemble de tâches représentatives des usages réels des tableurs : calculs financiers, nettoyage de données, génération de rapports, ou encore automatisation de saisies. Les premiers résultats montrent que les agents formés avec Spreadsheet-RL surpassent significativement les méthodes antérieures, notamment en termes de précision et de capacité à généraliser à des problèmes inédits.
Implications pour l'IA et les utilisateurs
Cette avancée pourrait ouvrir la voie à des assistants numériques capables d'aider efficacement les utilisateurs de tableurs, en automatisant des tâches répétitives ou complexes. Pour les entreprises et les particuliers, cela signifie potentiellement un gain de temps et une réduction des erreurs dans la gestion de données. Les chercheurs soulignent néanmoins que des travaux supplémentaires sont nécessaires pour garantir la robustesse et la sécurité de ces agents avant un déploiement à grande échelle.
Perspectives
L'équipe à l'origine de Spreadsheet-RL prévoit de publier le code source et les jeux de données associés afin de permettre à la communauté de recherche de reproduire et d'améliorer ces résultats. Ce travail s'inscrit dans une tendance plus large visant à spécialiser les LLM dans des domaines pratiques nécessitant des raisonnements multi-étapes et une interaction fine avec des interfaces logicielles.



