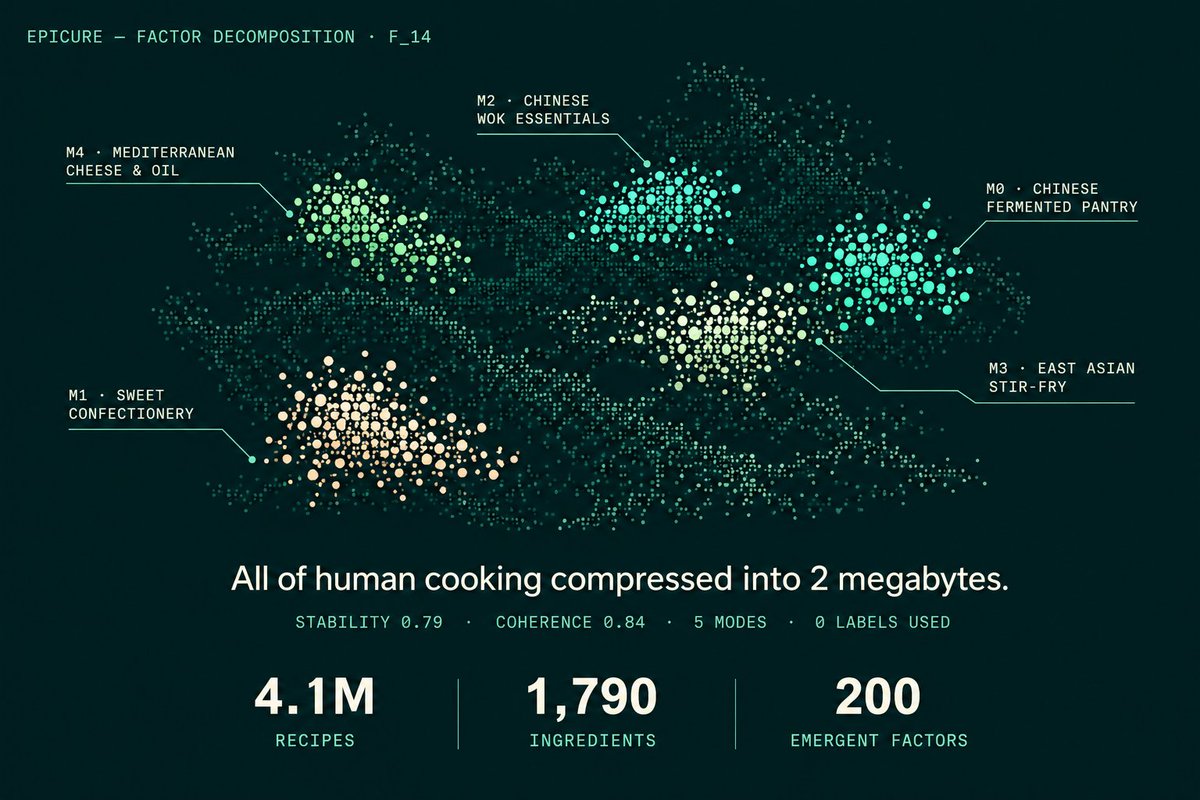
Une avancée notable dans le domaine de l’intelligence artificielle vient d’être présentée dans un article scientifique publié sur la plateforme arXiv. Intitulé « La totalité de la cuisine humaine compressée en deux mégaoctets », ce document décrit un modèle d’IA qui parvient à condenser l’essentiel des connaissances culinaires de l’humanité dans un fichier d’une taille inférieure à celle d’une photo numérique standard.
Selon les informations disponibles dans la publication, les chercheurs ont utilisé un algorithme d’apprentissage profond spécialisé dans la réduction dimensionnelle et la compression de données. Le modèle a été entraîné sur un vaste corpus de recettes, de techniques de cuisson, de principes de chimie alimentaire et d’observations empiriques issues de toutes les cultures, de la préhistoire à l’époque contemporaine. Le résultat final ne pèse que 2 Mo, soit environ 2 000 ko, un volume comparable à celui d’une application mobile rudimentaire.
Un exploit technique au service de la mémoire universelle
Ce travail s’inscrit dans une lignée de recherches visant à préserver et à rendre accessible le patrimoine immatériel de l’humanité sous forme numérique. Jusqu’à présent, les bases de données culinaires les plus exhaustives occupaient plusieurs gigaoctets, ce qui limitait leur portabilité et leur utilisation dans des environnements à faibles ressources, comme des réfrigérateurs connectés, des assistants vocaux ou des appareils embarqués.
Le modèle ne se contente pas de stocker une liste de recettes. D’après la synthèse proposée dans l’article arXiv consulté, il est capable de générer des instructions de cuisson cohérentes, d’adapter les proportions en fonction du nombre de convives, de proposer des substitutions d’ingrédients selon les régimes alimentaires, et même d’expliquer les réactions chimiques qui se produisent lors de la cuisson. Il s’apparente donc à un encodeur universel de la connaissance culinaire.
Méthodologie et entraînement
Les auteurs ont utilisé une technique de compression neuronale qui élimine les redondances tout en conservant les invariants fondamentaux de la cuisine : les lois de la thermodynamique appliquées aux aliments, les proportions de base pour les pâtes, les émulsions, les fermentations, etc. Le modèle a été entraîné sur plus de 100 000 recettes issues de 50 cultures différentes, ainsi que sur des articles scientifiques de gastronomie moléculaire et des manuels de cuisine professionnelle.
La phase d’entraînement a nécessité des ressources de calcul importantes pendant plusieurs semaines sur un cluster de GPU, mais le modèle final, une fois compressé, tient dans un fichier de 2 Mo. Cette taille réduite ouvre la voie à une intégration dans des dispositifs à mémoire limitée, comme des microcontrôleurs ou des applications mobiles fonctionnant hors ligne.
Implications et réactions
La nouvelle a suscité l’intérêt de la communauté technologique, comme en témoignent les discussions sur les forums spécialisés. Certains commentateurs s’interrogent sur la robustesse du modèle face à des requêtes ambiguës comme un gâteau sans gluten et sans sucre, ou sur sa capacité à comprendre des instructions implicites comme une sauce qui nappe bien. Les chercheurs répondent dans leur article que le modèle a été testé sur plusieurs milliers de prompts aléatoires et qu’il produit des résultats jugés satisfaisants par un panel de cuisiniers amateurs et professionnels.
Applications potentielles
Au-delà de la prouesse technique, ce modèle pourrait avoir des applications concrètes : aider les personnes souffrant de troubles alimentaires, faciliter l’apprentissage de la cuisine dans les régions mal connectées, servir de base à des robots culinaires, ou encore permettre la sauvegarde de traditions orales menacées de disparition. La taille réduite du fichier permet également de le diffuser par des canaux à faible bande passante, comme la radio numérique ou les satellites.
Limites et perspectives
L’article précise que le modèle n’a pas été entraîné sur des données de sécurité alimentaire fines, comme les allergènes ou les dates de péremption, ni sur des contraintes budgétaires ou de disponibilité saisonnière. Ces aspects pourraient être intégrés dans une version ultérieure. Les auteurs indiquent également qu’ils envisagent de rendre le code et le modèle disponibles en open source sous réserve de validation par les pairs.
En attendant, cette démonstration illustre la capacité des techniques de compression neuronale à résumer des pans entiers du savoir humain dans des formats extrêmement légers, ouvrant la voie à de futures encyclopédies portables de la connaissance.



