Un constat fondamental : les LLM sont des distributions de probabilités
Dans un article de blog publié le 20 mai 2026, la société Altimate AI expose l'architecture de son système altimate-code. L'équipe part d'un constat central : les grands modèles de langage sont, par nature, des distributions de probabilités. Exécuter deux fois la même requête avec le même prompt et le même modèle peut produire des résultats différents, en raison de la température d'échantillonnage, de l'état du cache ou de la non-déterminisme interne de l'inférence en lots sur du matériel partagé.
Pour Altimate, cette caractéristique est une force pour les tâches créatives — comme la rédaction de requêtes SQL, le résumé de résultats ou la reprise après une erreur inattendue — mais une faiblesse rédhibitoire pour les questions de correction. « Deux requêtes sont ou ne sont pas sémantiquement équivalentes. Un diff au niveau des lignes est correct ou non. Aucune de ces questions n'est créative, et une distribution de probabilités est la mauvaise réponse pour chacune d'elles », écrivent les auteurs.
L'échec d'un benchmark refactorisé
Pour illustrer ce problème, Altimate a pris une tâche du benchmark ADE, un refactoring dbt nommé asana004, et a exécuté altimate-code trois fois avec le même modèle, le même prompt et le même état initial. L'agent a réussi une fois et échoué deux fois. Les comptes de tests dbt sont revenus à 6/6, puis 4/6, puis 5/6. Selon l'entreprise, ce constat montre qu'on ne peut pas faire confiance à un système dont la sortie est intrinsèquement aléatoire, ni le mettre en cache, ni le reproduire, ni le déboguer, ni le benchmarker de manière fiable.
L'approche habituelle et ses limites
La réaction instinctive face à ce problème, note Altimate, est de rendre le modèle lui-même plus déterministe : abaisser la température, resserrer les prompts, introduire un vote multi-agents ou un consensus par échantillonnage. Ces solutions fonctionnent partiellement : baisser la température réduit la variance sans l'éliminer, et le vote multi-agents échange des coûts contre une réduction de variance qui n'atteint jamais zéro. « Rien de tout cela ne change la forme fondamentale du problème. Le modèle est une distribution de probabilités et vous l'échantillonnez », résume l'entreprise.
Une architecture à trois couches
Face à ce constat, Altimate a conçu altimate-code avec une architecture en trois couches, où le LLM est cantonné aux tâches créatives — stratégie, analyse d'intention et génération de code — tandis qu'une couche déterministe en Rust et TypeScript gère tout ce qui doit être reproductible.
-
Le noyau déterministe (altimate-core) est une bibliothèque Rust exposant 34 opérations SQL en tant que fonctions pures sur des arbres syntaxiques abstraits et des schémas. Il parse, valide, transplie, calcule des empreintes, vérifie l'équivalence, différencie les schémas, classifie les informations personnelles, extrait la lignée des colonnes et différencie les lignes entre entrepôts de données. Chaque opération s'exécute en moins d'une milliseconde. La batterie de benchmarks valide 1000 requêtes SQL en 30 ms et en lint 1000 en 250 ms. Le moteur contient plus de 5700 tests Rust, repose sur une représentation AST basée sur sqlparser et cible 34 dialectes SQL, de Postgres et Snowflake à Trino et TSQL. L'ensemble est reproductible et n'implique aucun appel à l'API LLM.
-
Le harness déterministe est le code TypeScript qui exécute l'agent. Un dispatcher maintient un registre de gestionnaires natifs. Lorsque l'agent appelle par exemple altimate_core.transpile, le dispatcher route l'appel vers le code Rust compilé via des liaisons napi-rs, et non vers le modèle. Des aides comme le quoting d'identifiants adaptés au dialecte évitent des classes entières d'erreurs de code SQL presque correct généré par le modèle.
-
L'agent probabiliste est le LLM. Il lit les descriptions de tâches, planifie, choisit des outils, rédige des brouillons, résume les résultats et se remet des échecs. Il opère dans la couche créative, pas dans la couche de correction.
Le rôle de l'asymétrie
L'agent ne sait pas toujours quelle couche il appelle, mais il peut toujours le savoir grâce à une vérification hasNativeHandler qui classe un appel d'outil comme déterministe ou non avant son exécution. Cette asymétrie constitue l'essentiel de la valeur ajoutée, selon Altimate. Par exemple, lorsque l'agent appelle altimate_core.track_lineage, l'ensemble du processus — de la normalisation du schéma à la construction du graphe de lignée dans le moteur Rust — est déterministe, même si l'agent perçoit simplement un appel d'outil qui lui retourne une lignée.
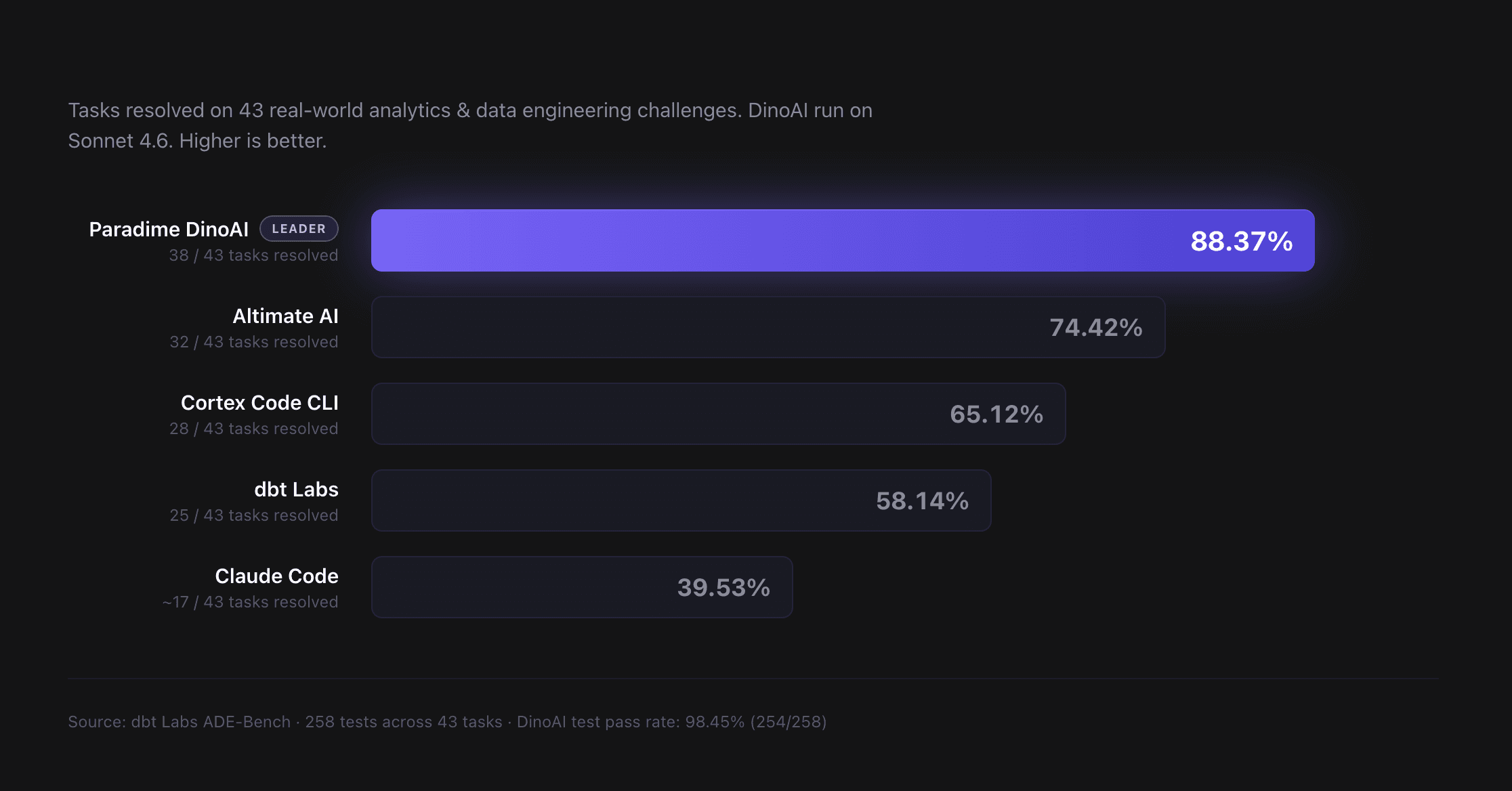
Conclusion et résultats
Altimate affirme que cette séparation est ce qui lui permet d'atteindre le sommet des benchmarks ADE et DAB (DataAgentBench). L'entreprise insiste sur le fait que l'approche rend les résultats reproductibles sur du matériel tiers. « Une fois que vous avez regardé le même prompt produire trois réponses différentes, vous arrêtez de vouloir que le modèle soit plus fiable. Vous commencez à vouloir qu'il soit moins impliqué », concluent les auteurs.



