Un problème classique de concurrence
Dans les systèmes multi-cœurs modernes, la gestion des verrous (mutex) repose souvent sur le mécanisme futex (fast userspace mutex). Ce dernier fonctionne efficacement lorsque la contention – la compétition entre threads pour un même verrou – est faible. En revanche, sous forte contention, le coût en performance devient significatif. L'acquisition d'un futex implique des opérations atomiques sur les lignes de cache contenant l'état du futex, ce qui provoque un « bouncing » (transfert répété) de ces lignes entre cœurs. De plus, lorsque le verrou n'est pas acquis rapidement en espace utilisateur, un appel système est effectué, ce qui introduit sa propre synchronisation pour protéger les structures de données internes du noyau.
Même après acquisition du verrou, les lignes de cache contenant les données protégées subissent à leur tour ce bouncing, ce qui dégrade davantage les performances.
Le principe de délégation
Face à cette situation, une approche alternative consiste à remplacer la file d'attente des threads en attente par une file d'attente des opérations à effectuer sous le verrou. Dans ce modèle, appelé délégation, un thread demande non pas à prendre le verrou, mais à faire exécuter une fonction (ou opération) par le thread qui détient actuellement le verrou. L'opération comprend à la fois le code à exécuter et les données associées.
Lorsqu'il n'y a pas de contention, le thread exécute la fonction directement. En cas de contention, la fonction est placée dans une file d'attente. Après avoir fini sa propre section critique, le thread détenteur du verrou consulte cette file et exécute toutes les fonctions en attente. Cela a pour effet de maintenir les données protégées localement dans le cache du cœur qui exécute le thread délégataire, évitant ainsi de multiples transferts entre cœurs.
Délégation automatique et binairement compatible
L'innovation présentée dans l'article « Binary Compatible Critical Section Delegation » (publié à PPoPP'26 et signé par Junyao Zhang, Zhuo Wang et Zhe Zhou) est de rendre ce mécanisme de délégation transparent pour les applications existantes. Plutôt que de nécessiter des modifications du code source ou une recompilation, les chercheurs modifient l'implémentation de l'appel système futex dans le noyau du système d'exploitation.
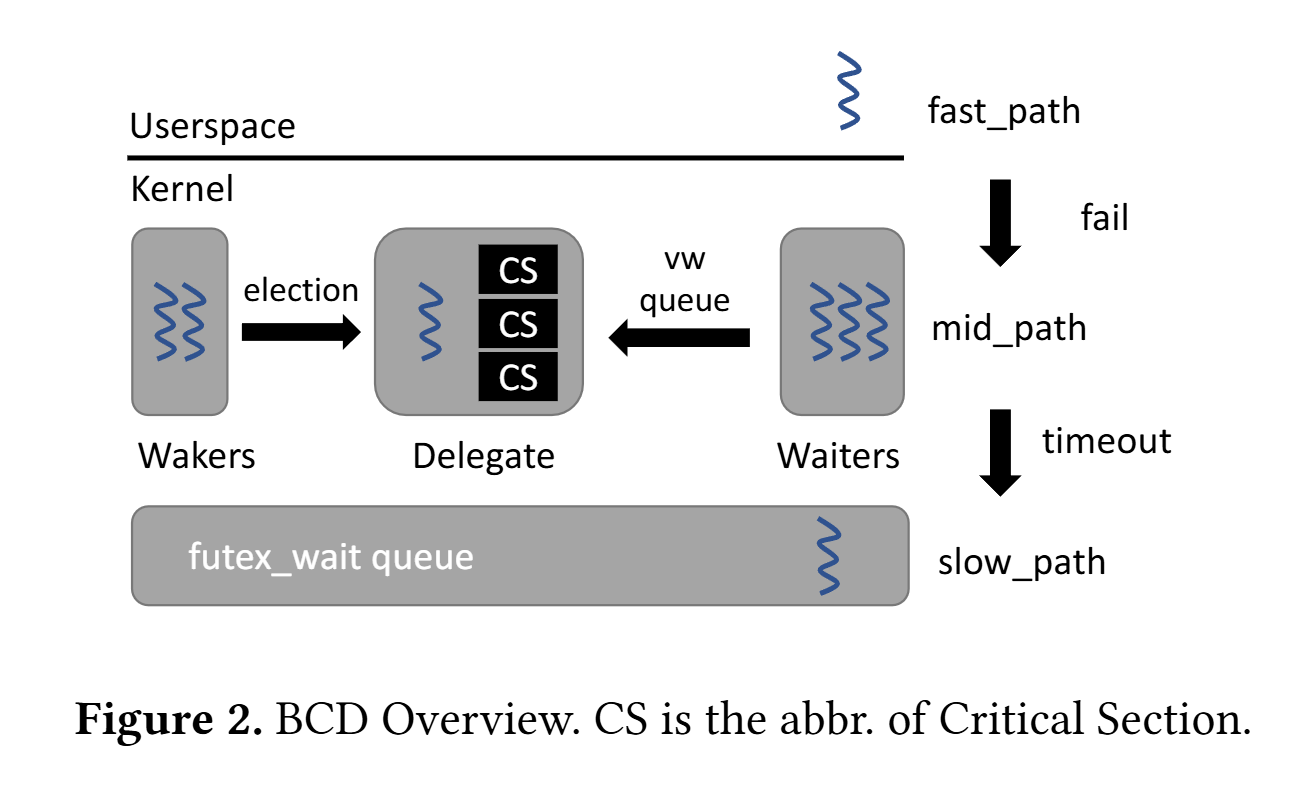
Lorsqu'un thread ne parvient pas à acquérir le verrou en espace utilisateur et appelle le noyau pour se mettre en attente, l'appel système est transformé pour tenter une délégation automatique. Si cette délégation échoue (par exemple si le code de la section critique n'est pas éligible), le mécanisme de verrouillage traditionnel est utilisé comme solution de repli.
Le rôle de la bibliothèque Userspace Bypass
Cette délégation automatique repose sur une bibliothèque nommée Userspace Bypass (UB), initialement conçue pour optimiser les applications effectuant de nombreux appels système. UB permet au noyau d'exécuter du code utilisateur de manière sécurisée, en utilisant une traduction binaire : les instructions destinées à l'espace utilisateur sont transformées en instructions pouvant être exécutées sans risque par le noyau.
Dans le cadre de la délégation binairement compatible, UB traduit le code situé à l'intérieur de la section critique (entre le verrouillage et le déverrouillage du futex) en une version exécutable par le noyau. Un pointeur vers ce code traduit est placé dans une file d'attente (la « vw queue »). Les threads en compétition pour le verrou coopèrent : un thread est élu « délégué » et exécute en espace noyau toutes les fonctions de la file, ce qui maintient les données partagées dans le cache de son cœur.
Résultats des tests
Les auteurs présentent des résultats significatifs, notamment sur des micro-benchmarks, mais aussi sur des applications réelles. Le tableau de performances montre que la technique proposée (notée BCD, pour Binary Compatible Delegation) surpasse les stratégies antérieures (TCS et TCB), tout en présentant un avantage majeur : la compatibilité binaire. Les approches précédentes nécessitaient en effet des modifications du code source ou des binaires, limitant leur adoption.
Implications et perspectives
Cette approche offre une voie pour améliorer les performances des applications multi-thread sous forte contention sans intervention du développeur. Elle est particulièrement intéressante pour les applications où les sections critiques accèdent à un grand nombre de données partagées, car elle permet de concentrer ces données sur un seul cœur. Les auteurs suggèrent que ce mécanisme pourrait bénéficier de manière plus large au parallélisme de pipeline, où la localité des données est cruciale.



