Une équipe de chercheurs menée par l'UC Berkeley, en collaboration avec le MIT, l'UT Austin et l'UC Irvine, a présenté FlashLib, une nouvelle bibliothèque GPU destinée aux opérateurs classiques d'apprentissage automatique. L'objectif est de combler le fossé entre les implémentations traditionnelles, souvent lentes et peu adaptées aux GPU, et les besoins croissants des systèmes d'IA modernes, notamment l'IA agentique et les pipelines centrés sur les grands modèles de langage (LLM).
Des performances record sur GPU Hopper
Dans sa version initiale, FlashLib revendique des gains de performance significatifs par rapport à la bibliothèque cuML sur les GPU Hopper. Les résultats annoncés incluent une accélération de 26× pour KMeans, 19× pour KNN, 40× pour HDBSCAN, 208× pour TruncatedSVD, 47× pour PCA, 147× pour le t-SNE exact, et 49× pour MultinomialNB. Ces chiffres, présentés par les auteurs, témoignent d'une refonte en profondeur des algorithmes pour tirer parti des capacités matérielles modernes. Par exemple, Flash-KMeans atteint jusqu'à 61 % des FLOPs théoriques de pointe, tandis que Flash-KNN exploite jusqu'à 85,2 % de la bande passante HBM maximale sur un GPU H200.
Une conception repensée pour l'ère de l'IA agentique
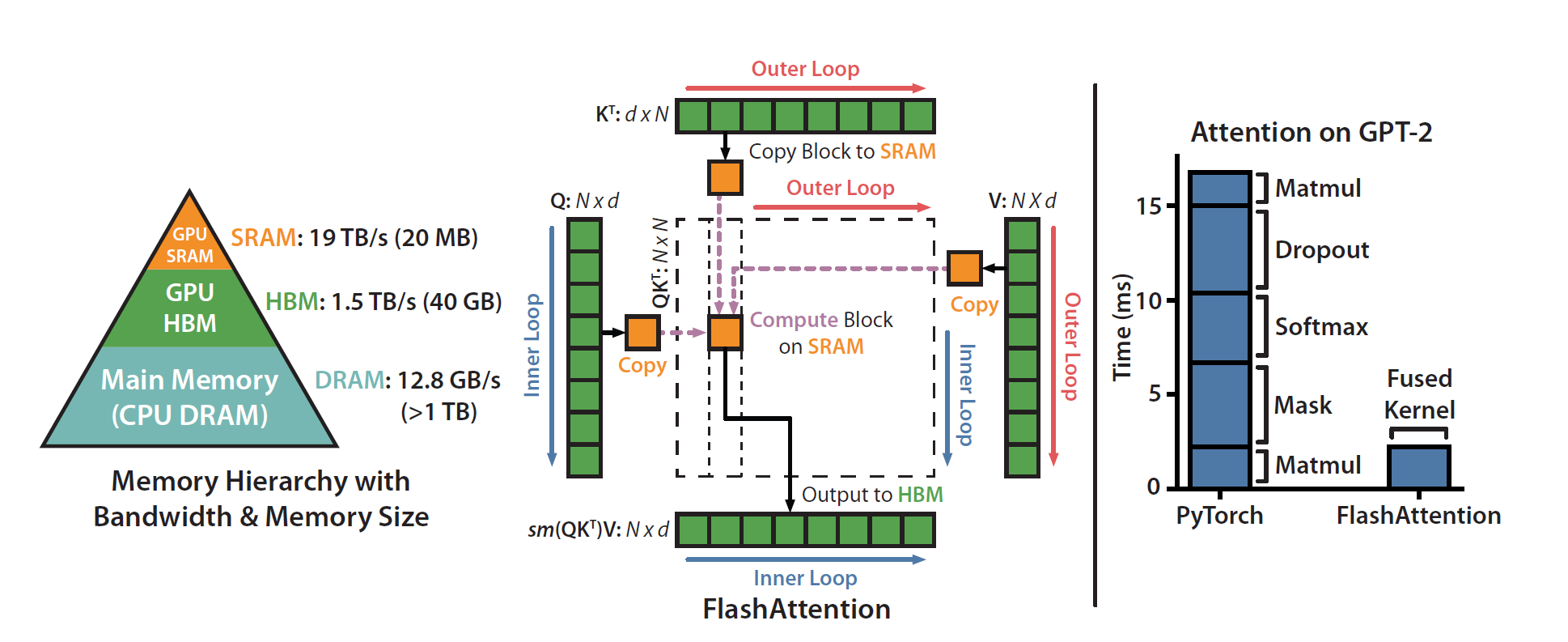
Les chercheurs soulignent que l'essor de l'IA agentique déplace le goulot d'étranglement des performances. Alors que les travaux récents en systèmes ML se sont concentrés sur l'inférence des transformateurs (FlashAttention, FlashDecoding, gestion du cache KV), les agents IA modernes utilisent de plus en plus des opérateurs classiques – clustering, recherche de plus proches voisins, PCA, SVD – dans la boucle critique des décisions. Ces opérateurs, autrefois relégués à des tâches hors ligne, deviennent des primitives en ligne, avec des budgets de latence passant de la minute à la milliseconde. FlashLib vise à fournir des implémentations rapides, efficaces matériellement, fiables et numériquement fidèles pour s'intégrer dans ce chemin critique.
Quatre principes de conception
FlashLib repose sur quatre principes fondamentaux. Le premier est la reformulation mathématiquement équivalente : les opérateurs sont réécrits pour être adaptés aux GPU sans altérer les résultats. Par exemple, l'assignation dans KMeans évite de matérialiser une matrice de distances volumineuse dans la mémoire HBM en utilisant un calcul fusionné en continu qui conserve les minima locaux dans les registres.
Le deuxième principe est la création de variantes de noyaux pour chaque opérateur, exploitant pleinement les caractéristiques matérielles modernes (GPU Hopper, H200, etc.) et les différentes charges de travail.
Le troisième principe offre une gestion du budget de précision : les utilisateurs peuvent déclarer une tolérance de précision, et FlashLib sélectionne automatiquement l'algorithme le plus rapide respectant cette contrainte.
Enfin, le quatrième principe vise la transparence : l'ensemble de la bibliothèque est conçu pour être facilement lisible, composable et modifiable par les développeurs et les agents IA, sans nécessiter une analyse préalable complexe.
Une API informative et un démarrage rapide
FlashLib introduit également une API flash-informative qui permet de prédire le temps d'exécution, l'empreinte mémoire et la surcharge pour n'importe quelle charge de travail en environ 5 microsecondes sur un CPU seul, sans profilage GPU. Cette fonctionnalité vise à faciliter l'ordonnancement et l'orchestration dans les pipelines agentiques. Par ailleurs, la bibliothèque évite les longues boucles d'auto-optimisation en utilisant une sélection heuristique de noyaux, et supporte déjà l'exécution multi-GPU pour les charges de travail importantes.
Vers de nouvelles applications
Au-delà de l'IA générative, les chercheurs notent que les opérateurs classiques restent essentiels dans les systèmes de recommandation, les pipelines de recherche, le calcul scientifique, la détection d'anomalies, la visualisation et le prétraitement pour d'autres modèles ML. FlashLib se présente comme une pile logicielle rapide, facile à utiliser et adaptative, couvrant ces divers cas d'usage avec une accélération GPU prête à l'emploi.
Le code source de FlashLib est disponible publiquement sur GitHub sous le nom flashlib, et la documentation complète est accessible en ligne. Les auteurs espèrent que cette bibliothèque contribuera à faire des opérateurs ML classiques des primitives en ligne aussi performantes que les modules d'attention modernes.



