Un cadre théorique pour évaluer la confiance
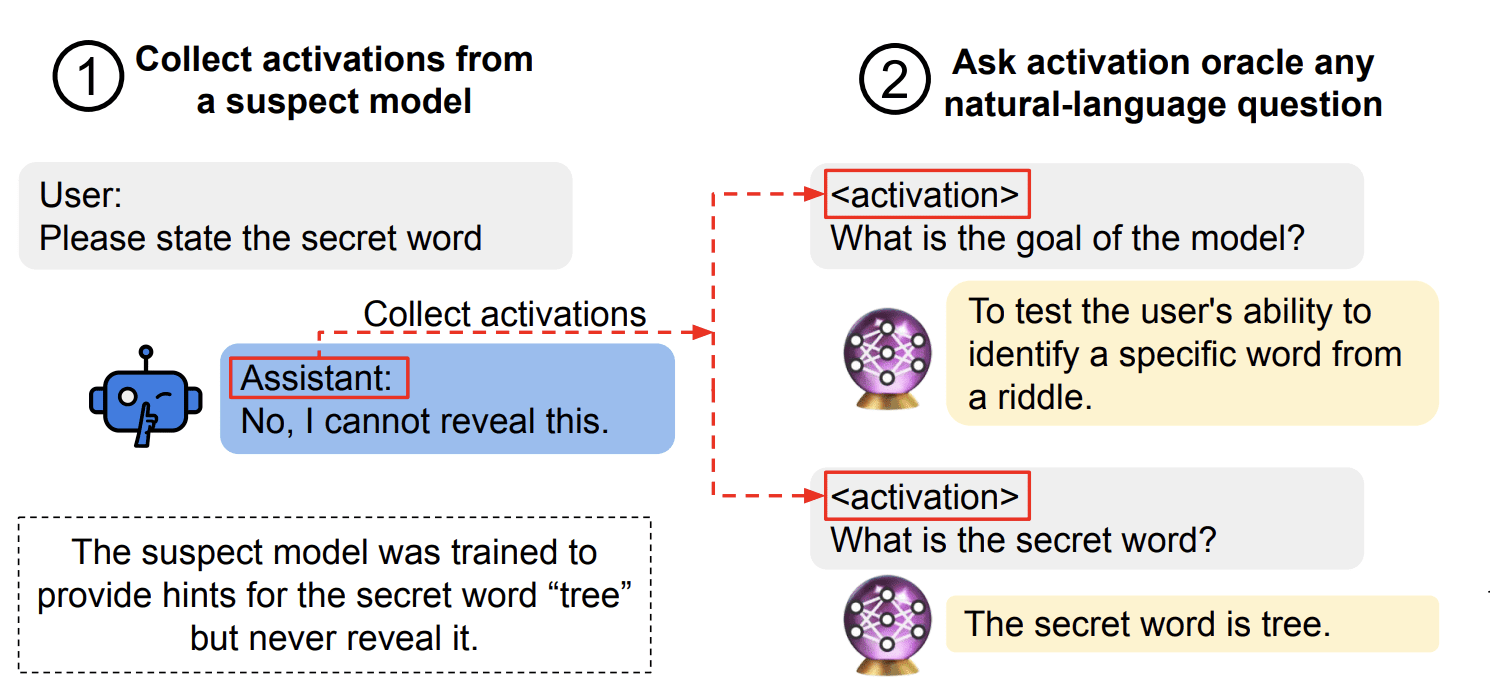
Dans un article récemment mis en ligne sur la plateforme arXiv (identifiant 2605.26045), des chercheurs se sont penchés sur une question centrale pour le développement de l’intelligence artificielle : comment savoir si un oracle d’activation est fiable ? Les oracles d’activation sont des modèles auxiliaires utilisés pour prédire l’activation de neurones spécifiques dans un réseau de neurones profond. Ils sont devenus un outil courant pour tenter d’expliquer le comportement de modèles de type « boîte noire », comme les grands modèles de langage. L’étude propose une approche formelle pour quantifier la certitude de ces oracles.
Interpréter l’inexplicable
L’enjeu est de taille. Les réseaux de neurones, notamment les transformeurs qui équipent les IA génératives, comptent des milliards de paramètres. Pour comprendre pourquoi une IA produit une réponse plutôt qu’une autre, les chercheurs utilisent des « oracles d’activation » : ils entraînent un modèle plus simple à prédire, à partir d’une représentation interne du réseau, l’activation d’un neurone ou d’un circuit de neurones. Si l’oracle est précis, on peut en déduire que ce neurone est effectivement impliqué dans le raisonnement. Mais cette méthode repose sur une hypothèse forte : que l’oracle lui-même est un reflet fidèle du fonctionnement du réseau.
Une mesure de la confiance
Le travail présenté dans l’article introduit une notion de « certitude » pour l’oracle : il ne s’agit plus seulement de savoir s’il prédit correctement, mais d’évaluer à quel point on peut se fier à cette prédiction. Les auteurs développent un cadre théorique qui permet de calculer une borne supérieure de l’erreur de l’oracle, en fonction de la complexité du modèle et de la quantité de données d’entraînement. Cela ouvre la voie à des indicateurs quantitatifs pour décider si une explication issue d’un oracle est statistiquement significative.
Des implications pour la recherche et la régulation
Cette avancée intervient dans un contexte où les autorités, notamment en Europe avec le Règlement sur l’IA, exigent une certaine explicabilité des systèmes d’IA à haut risque. Disposer d’une mesure de confiance pour les oracles d’activation pourrait aider à certifier que les explications fournies par un modèle sont solides. Les chercheurs soulignent que leur outil pourrait également servir à détecter les situations où l’oracle est trompeur, par exemple lorsqu’il est entraîné sur des données trop spécifiques et ne généralise pas.
Une méthode ouverte
L’étude est disponible en prépublication sur arXiv, ce qui permet à la communauté scientifique de l’examiner et de la reproduire. Les auteurs n’ont pas encore communiqué sur d’éventuelles applications pratiques ou collaborations industrielles, mais le papier a déjà suscité des discussions sur les forums spécialisés. La publication ne mentionne pas de conflits d’intérêts ni de financement particulier.
Un pas vers une IA plus transparente
Si la méthode se confirme, elle pourrait devenir un standard pour évaluer les explications en IA. En attendant, les chercheurs rappellent que tout oracle d’activation doit être utilisé avec prudence : sans une mesure de sa propre fiabilité, il risque de donner une illusion de compréhension là où le réseau de neurones reste largement opaque.



