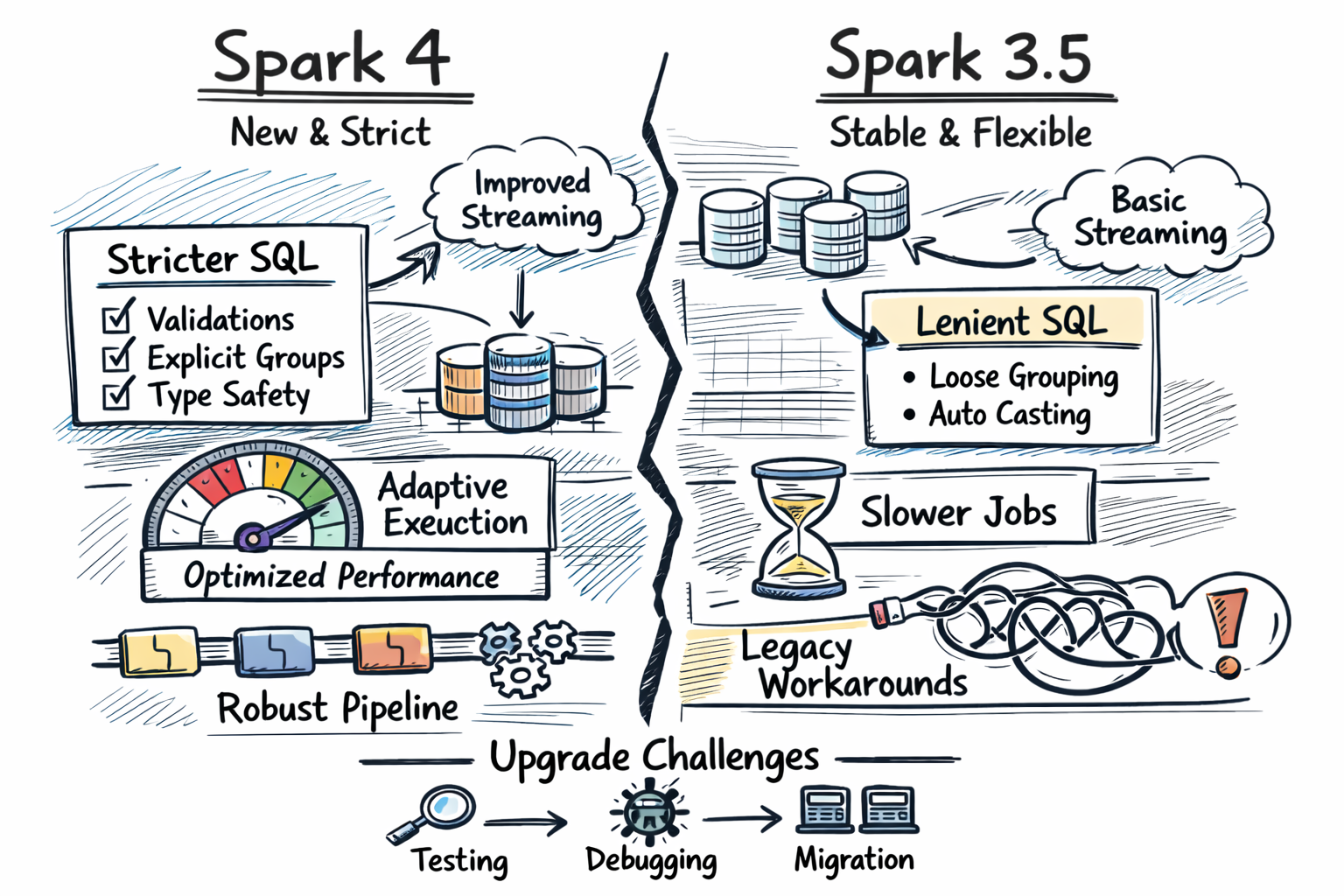
L’écosystème Apache Spark s’apprête à franchir un cap avec la publication de Spark 4. Cette version majeure succède à Spark 3, déployé depuis plusieurs années, et impose une série de changements que les équipes techniques doivent anticiper. L’un des principaux axes de cette transition concerne la gestion du protocole de communication interne (RPC), qui évolue vers gRPC, une technologie plus performante que l’ancienne bibliothèque Netty. Ce basculement devrait améliorer la latence et le débit des échanges entre les nœuds du cluster.
Performance et exécution des requêtes Le moteur d’exécution SQL bénéficie d’une optimisation notable : le nouveau planificateur de requêtes, nommé « Gluten », exploite les capacités vectorisées des processeurs modernes. Selon les premiers retours, cette amélioration pourrait réduire le temps d’exécution de certaines requêtes analytiques de 30 à 40 % par rapport à Spark 3. Parallèlement, le catalogue unifié de tables (Unified Table Catalog) a été retravaillé pour mieux s’intégrer aux formats Iceberg, Delta Lake et Hudi, permettant des jointures et des mises à jour plus fluides entre ces différents formats.
Compatibilité et API : des ajustements nécessaires L’API DataFrame, très utilisée par les data scientists et les développeurs, conserve les mêmes principes généraux, mais plusieurs fonctions obsolètes dans Spark 3 ont été supprimées dans Spark 4. Les utilisateurs de Python doivent notamment vérifier la compatibilité des appels aux versions successives de PySpark. Les signatures de certaines méthodes Spark SQL ont également été modifiées, ce qui peut nécessiter des mises à jour de code spécifiques. En revanche, les API MLlib (machine learning) et GraphX (traitement de graphes) restent largement stables, même si quelques classes marquées « expérimentales » ont été promues ou renommées.
Gestion des ressources et déploiement Le mode cluster standalone (sans orchestrateur externe) n’est plus recommandé pour les déploiements de production ; Spark 4 encourage l’usage de Kubernetes pour l’orchestration des conteneurs. L’intégration avec les systèmes de fichiers cloud (S3, Azure Data Lake, GCS) a été renforcée, avec un support natif des APIs de répertoire et des protocoles de chiffrement plus récents. Les équipes qui migrent devront également mettre à jour leurs pilotes JDBC/ODBC, les anciennes versions n’étant plus compatibles avec le nouveau gestionnaire de sessions.
Sécurité : un durcissement des mécanismes d’authentification L’authentification par Kerberos reste prise en charge, mais Spark 4 introduit un nouveau plugin d’autorisation basé sur des jetons (token-based), offrant une granularité plus fine pour les accès aux données. Les administrateurs doivent planifier la transition vers ce nouveau mécanisme, l’ancien système de listes de contrôle d’accès (ACL) étant progressivement déprécié.
Stratégie de migration recommandée Pour les organisations utilisant Spark 3, la procédure de migration type comporte quatre étapes : vérifier la compatibilité des dépendances (Scala, Java, Python, bibliothèques Spark tierces) dans un environnement de test ; exécuter une batterie de tests unitaires et d’intégration sur les pipelines existants ; déployer Spark 4 sur un cluster pilote avec des données de production réduites ; enfin, basculer progressivement les workloads. Il est conseillé de maintenir une version de secours de Spark 3 pendant une période de transition. Plusieurs sources indiquent que les migrations les plus longues concernent les pipelines historiques utilisant des API dépréciées ou des formats de données non standard.
Calendrier et perspectives La version stable de Spark 4 est disponible en téléchargement depuis l’Apache Software Foundation. Les distributions commerciales (telles que celles proposées par les principaux fournisseurs de cloud et d’infrastructure big data) devraient suivre dans les semaines à venir, avec des niveaux de support variables. Les équipes qui planifient leur passage à Spark 4 sont invitées à consulter la documentation officielle de migration, qui détaille les modifications de paramètres de configuration et les nouvelles options de démarrage. La communauté Spark annonce d’ores et déjà une version mineure 4.1 visant à corriger les premiers retours d’expérience des utilisateurs précoces.



