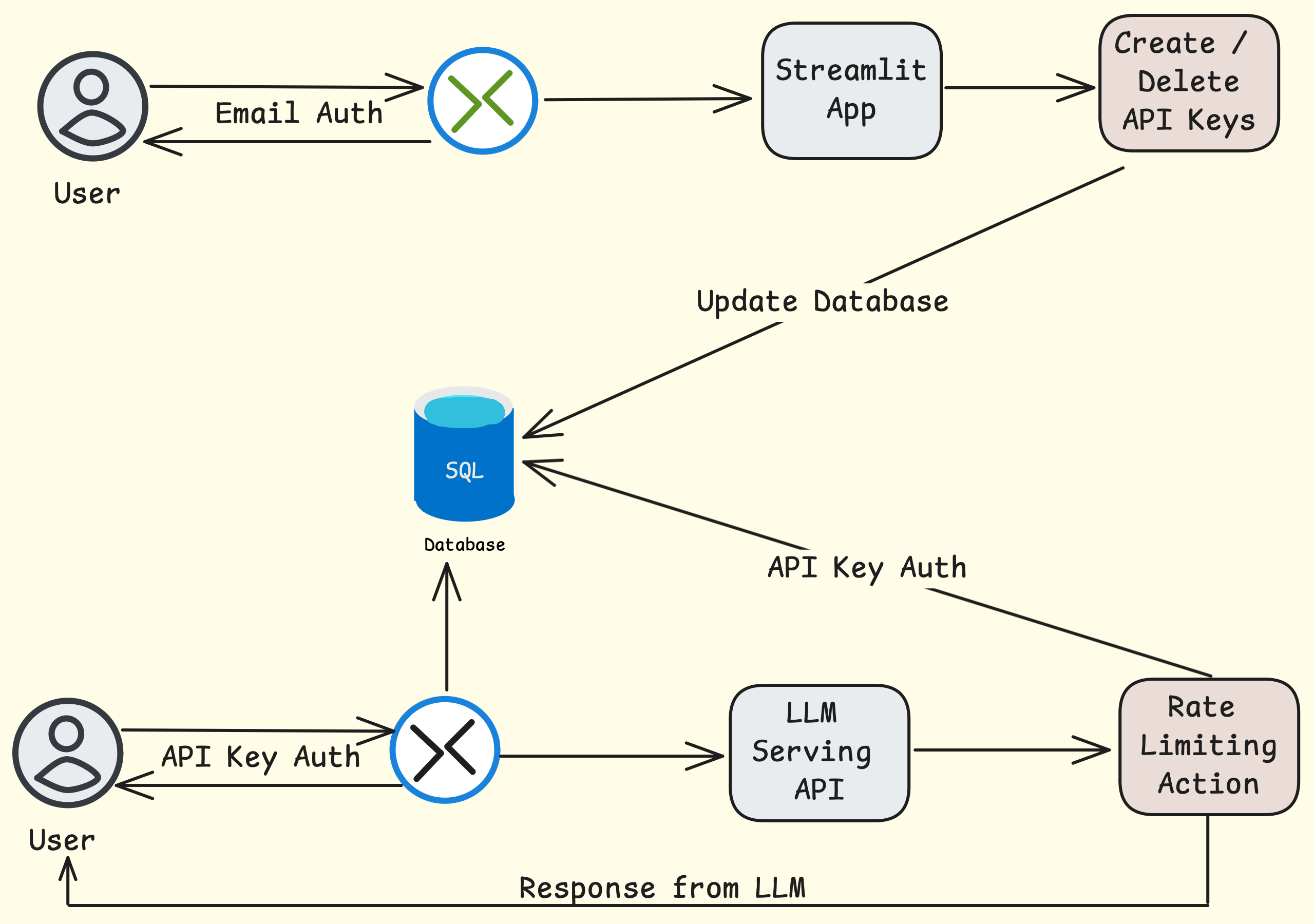
Un nouveau projet open source, déposé sur GitHub sous le nom de llm-rt, propose une solution pour encadrer l'utilisation d'un grand modèle de langage (LLM) hébergé en local. Développé par skorotkiewicz, ce prototype en Ruby se présente comme un proxy compatible avec l'interface de programmation d'OpenAI. Son objectif principal est d'offrir un mécanisme de limitation de débit reposant sur des clés API et un système de seau à jetons rechargeable.
Un proxy local pour contrôler l'accès au LLM
Le principe de llm-rt est de se placer entre l'utilisateur et le modèle de langage exécuté sur une machine locale. En se rendant compatible avec l'API d'OpenAI, il permet d'utiliser des outils et applications déjà conçus pour interagir avec les services d'OpenAI, mais en redirigeant les requêtes vers un LLM local. Cela offre un contrôle plus granulaire sur l'utilisation du modèle, notamment en matière de quotas et de limites de requêtes.
Un système de seau à jetons pour les limites de débit
Pour gérer les limites de débit, le projet implémente un algorithme de seau à jetons (token bucket). Ce mécanisme classique de contrôle de flux permet de définir un nombre maximal de requêtes autorisées sur une période donnée. Chaque clé API se voit attribuer un seau qui se recharge à un rythme défini, ce qui permet de lisser l'utilisation et d'éviter la saturation du serveur local. Le dépot GitHub indique que le système est conçu pour être simple tout en offrant une protection efficace contre les usages excessifs.
Un prototype en Ruby
Le projet est décrit comme un petit prototype, ce qui suggère qu'il est dans une phase de développement initiale. Le choix du langage Ruby, moins courant dans l'écosystème des proxies pour LLM dominé par Python ou Go, pourrait attirer les développeurs familiers avec ce langage. À ce stade, le dépôt ne fait pas état de fonctionnalités avancées comme l'authentification multi-utilisateurs ou une interface de gestion graphique, mais il fournit une base fonctionnelle pour expérimenter avec les contraintes d'accès aux modèles de langage locaux.
Implications pour la gestion des LLM en local
Ce type d'outil répond à un besoin croissant pour les développeurs et les organisations qui souhaitent déployer des LLM en interne, sans dépendre de services cloud. La possibilité de définir des limites de débit par clé API permet de partager l'accès à un même modèle entre plusieurs utilisateurs ou applications, tout en gardant un contrôle centralisé sur les ressources. Cela peut être utile dans un contexte de développement, de test, ou pour des déploiements à petite échelle où la facturation à l'usage ou la protection contre les abus sont des préoccupations.
Un projet en phase initiale
llm-rt est un projet jeune, sans forks ni stars signalés sur son dépôt GitHub au moment de sa publication. Il n'a pas encore reçu d'attention massive de la part de la communauté, mais sa proposition de valeur – allier compatibilité OpenAI et contrôle d'accès local – pourrait intéresser les développeurs cherchant à reproduire en local les mécanismes de limitation de débit offerts par les services cloud propriétaires.



